
AWS has published a guide on using the Strands Agents SDK with Exa to build AI agents that can search the web and retrieve full page content during a reasoning loop.
The post says the integration is aimed at workflows that need current information for research, fact-checking and competitive intelligence. It also argues that traditional search APIs are often optimized for human browsing, not direct use by agents.
What the integration adds
According to AWS, the Exa integration is available through the strands-agents-tools package and gives agents two main capabilities:
- exa_search for semantic web search
- exa_get_contents for pulling full-page text from URLs
AWS says both tools are designed to return structured content that an LLM can use without extra parsing or markup cleanup.
How Strands Agents works
Strands Agents is described as an open source AWS framework that uses a model-driven approach. Developers provide a model, a system prompt and a tool list, and the model decides which tools to call and when to stop.
The post says the agent loop preserves context across iterations, allowing the model to combine prior tool results with new ones until it produces a final answer.
Search modes and content extraction
AWS says exa_search supports several search modes and filtering options, while exa_get_contents can retrieve cached or live-crawled page content.
| Tool | Purpose | Noted options |
|---|---|---|
| exa_search | Search the web using semantic queries | auto, fast, deep; category, domain, date and text filters |
| exa_get_contents | Retrieve full text from selected URLs | Cached results, live crawling, timeout controls, character limits |
The post says the search tool can be narrowed to categories such as news, research papers and GitHub repositories. It also says the content tool can fall back to live crawling when current page text is needed.
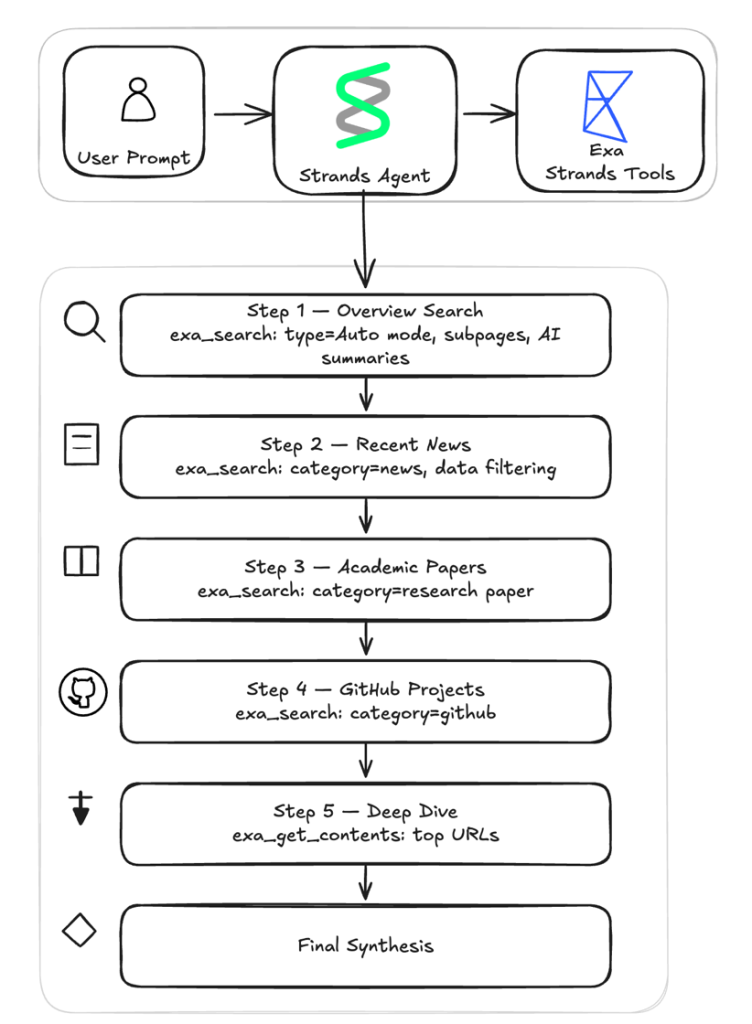
Example workflow in the post
AWS walks through a deep research assistant example that uses both tools in a multi-step workflow. The described process includes four targeted searches, full content extraction from promising URLs and a final synthesis step.
- Overview search with broad settings
- News search with a recent date window
- Research paper search for academic depth
- GitHub search for open source implementations
- Deep dive extraction from selected URLs
- Final synthesis into a structured brief
The post says the same two tools are reused across the workflow with different parameters, including category filters, date ranges, JSON schemas and live crawling settings.
Setup steps listed by AWS
To use the integration, AWS says users need Python 3.10 or later, an AWS account with Amazon Bedrock access, an Exa API key, and the strands-agents and strands-agents-tools packages.
- Set the EXA_API_KEY environment variable.
- Import exa_search and exa_get_contents from strands_tools.exa.
- Pass the tools to the agent.
- Invoke the agent with a task that requires web search.
Observability and debugging
The post says the workflow can be traced with Amazon Bedrock AgentCore Observability, which exposes tool calls and model invocations as spans. AWS says this helps developers inspect latency, parameters and token use across agent runs.
Why AWS says the pattern matters
In its conclusion, AWS says the combination of Strands Agents and Exa can help agents ground answers in current web information. The post says the pattern is not limited to research and can be extended to other agentic workflows.
Source: AWS, in a post on its Machine Learning blog.