Card fraud is one of those problems where timing matters as much as accuracy. Once a suspicious charge settles, the chance to stop it has already slipped away. Databricks is now spotlighting a new Solution Accelerator that tries to close that gap by pairing Spark Real-Time Mode with Lakebase, its managed PostgreSQL service, to build a full fraud detection workflow on a single platform.
The company says the reference implementation is open source and meant to be cloned into a Databricks environment. The goal is straightforward: ingest live transaction streams, score them quickly, explain why a payment looks risky, and surface the result in a monitoring app without forcing teams to stitch together a separate streaming stack.
That pitch matters because fraud teams have long had to choose between speed and simplicity. Ultra-low latency systems often rely on specialized tools sitting beside Spark, which can mean duplicate data, extra governance work, and more infrastructure to babysit. Databricks is arguing that Spark Real-Time Mode changes that tradeoff.
Why the timing problem is so hard
The blog frames fraud detection as a race between authorization and settlement. A stolen card number can be used repeatedly in minutes, and the longer a suspicious payment remains unblocked, the harder it is to recover funds. Databricks cites the Nilson Report’s estimate that financial institutions lose $33 billion a year to card fraud.
Most institutions already have models and rules in place, according to the post. The harder part is making those systems react fast enough to stop a transaction before it clears. That is where the company positions Real-Time Mode, or RTM, as the key piece of the stack.
What Spark Real-Time Mode brings to the table
RTM is described as an evolution of Spark Structured Streaming designed for latency-sensitive workloads. Databricks says it can process events in milliseconds and is up to 92% faster than Apache Flink in stateless transformation, join-based enrichment, and aggregation workloads.
The company also points to customers already using RTM. Coinbase, Databricks says, is computing more than 250 machine learning features with the system and has hit sub-100ms P99 processing latency.
For teams already invested in Spark, the bigger attraction may be operational simplicity. RTM runs inside the Spark engine rather than alongside it, which Databricks says reduces logic drift, keeps monitoring in one place, and avoids the need for a separate on-call setup just for streaming.
- No duplicated logic: the same feature engineering and preprocessing code can be reused in batch and streaming.
- One operational surface: existing Spark tooling, monitoring, and alerting still apply.
- Flexible latency choices: teams can switch to slower triggers when sub-second freshness is not worth the cost.
How the fraud demo is structured
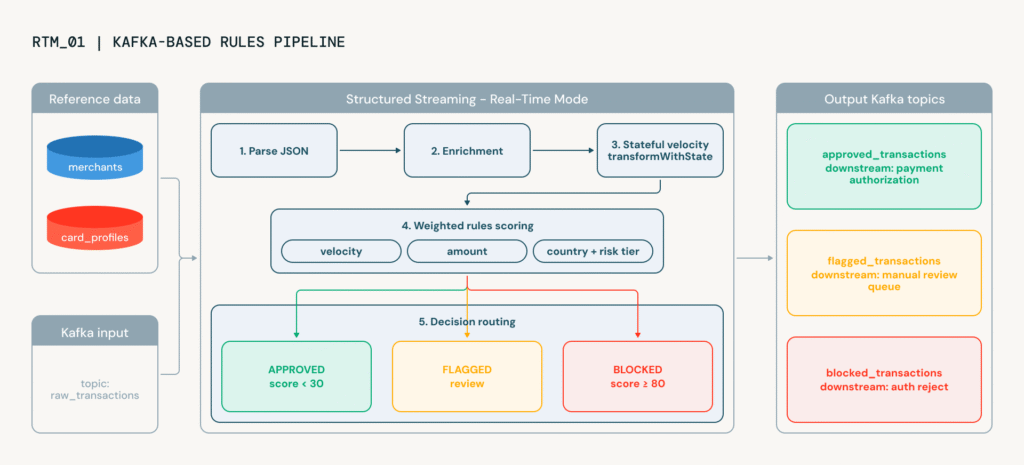
Databricks built the accelerator around a credit card fraud scenario that mirrors how real payment systems work. Transactions arrive from a streaming source such as Kafka or Kinesis and include fields like card ID, amount, merchant category, geographic coordinates, and channel.
Every transaction is evaluated against multiple signals, assigned a risk score, and routed into one of three outcomes: approved, flagged for review, or blocked. The company says the pipeline is designed to run within sub-300ms.
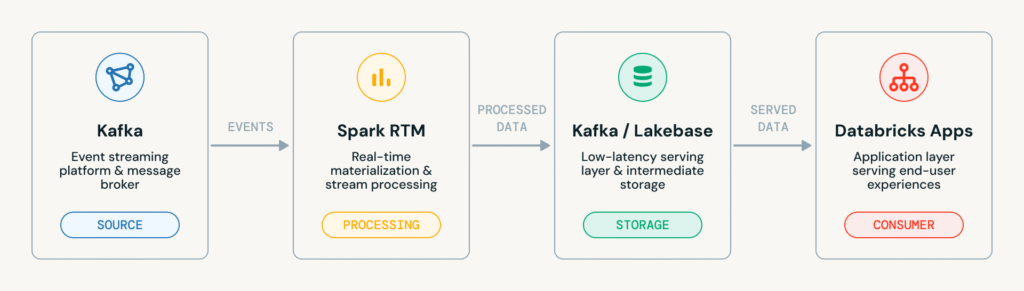
The architecture in the blog breaks into four main parts:
- Kafka as the transaction source
- Spark RTM as the real-time processing layer
- Kafka or Lakebase as the serving or intermediate layer
- Databricks Apps as the analyst-facing application layer
That setup is important because it shows how Databricks wants customers to think about fraud systems: not as a separate product silo, but as another workload running on the same platform as ETL, analytics, and machine learning.
From rules to machine learning
The accelerator does not stop at rules-based scoring. Databricks also includes an advanced path that moves the workflow toward machine learning, which is where many fraud teams eventually end up after rules start producing too many false positives.
In the blog’s example, the pipeline uses a RandomForest classifier trained on historical labeled data. MLflow handles experiment tracking and model versioning, while Lakebase acts as the online feature store-style serving layer for live card data such as velocity patterns, average transaction amounts, and geographic spread.
That combination is meant to solve a familiar problem in fraud detection: static thresholds can be easy to audit, but they are often blunt. A model can learn relationships between signals that are hard to express with fixed rules, while still keeping a record of how and when it was trained.
Lakebase and the live dashboard layer
Lakebase is another piece of the pitch. Databricks describes it as a fully managed, serverless Postgres database built into the platform, with sub-millisecond reads that make it suitable for real-time feature serving.
The accelerator streams per-card features into Lakebase using a custom writer, then reads those values back into the scoring pipeline. On the analyst side, a Streamlit-based Databricks Apps dashboard reads directly from Lakebase and refreshes every 10 seconds.
The dashboard is designed to give fraud teams a live view of:
- Total transactions scored
- Decision breakdowns across approved, flagged, and blocked payments
- Recent fraud scores with card-level detail
- Fraud probability distributions
That matters because fraud tools are only useful if operations teams can actually trust and inspect them. A fast scoring model is useful; a fast scoring model with a readable audit trail is better.
What Databricks says users can do next
The accelerator is laid out as a progression. Teams can start with a quick start notebook that uses synthetic data and does not require Kafka or other external services. From there, they can move into a full streaming pipeline, then add Lakebase and MLflow, and finally deploy the monitoring app.
Databricks says the quickest path is through Databricks Asset Bundles, which can provision a properly configured cluster and run the notebooks in sequence. The company also notes that Real-Time Mode is generally available across AWS, Azure, and GCP.
For data teams building fraud systems, the appeal is not just raw latency. It is the idea that the same platform can handle streaming, machine learning, governance, and operational monitoring without a pile of extra moving parts. That is a strong pitch in a space where every added system tends to create more friction before it creates more value.